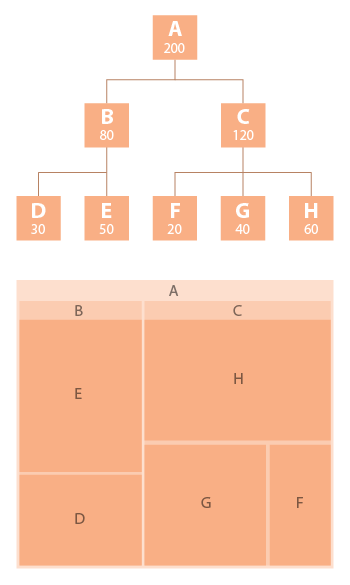
Representa estructuras jerárquicas mediante círculos en donde cada nodo se muestra como un círculo y sus subnodos aparecen dentro de él. El área de cada círculo puede ser proporcional a un valor numérico (por ejemplo: población, ventas, ingresos). Utiliza menos eficientemente el espacio que un treemap, pero ofrece una representación visual más estética y clara de las jerarquías. Se puede mostrar la jerarquía completa o eliminar niveles iniciales para mejorar la legibilidad.
Fuente:dataviz
Cuándo usarlo
Cuando se desea resaltar la estructura jerárquica de los datos.
En casos donde lo importante es la organización de grupos y subgrupos, no la comparación exacta de valores.
Para visualizaciones interactivas que permitan explorar los niveles de detalle.
Errores comunes a evitar
Incluir demasiados niveles jerárquicos en una sola vista
Esto produce un gráfico saturado y difícil de leer. Solución: usar versiones interactivas o limitar el número de niveles.
Pretender comparar valores con precisión
El área de los círculos no se percibe con exactitud a simple vista. Solución: si se requiere precisión, emplear gráficos de barras o de puntos.
Sobrecargar con etiquetas
Muchas etiquetas dificultan la lectura del gráfico. Solución: mostrar solo etiquetas clave o habilitar interacción con hover.
Escalado inadecuado de los tamaños
Si los valores son muy dispares, algunos círculos pueden resultar invisibles. Solución: aplicar transformaciones (logarítmica, raíz cuadrada) o segmentar los datos.
Usarlo como herramienta de comparación exacta
Este gráfico está diseñado para mostrar jerarquías, no para análisis cuantitativos precisos.
Dataset: Precios Agroindustria de Cacao (2012 - 2025)
Archivo:MAG_PreciosAgroindustriaCacao_2025Junio.csv Fuente: Ministerio de Agricultura y Ganadería (MAG), Ecuador Última actualización: Junio 2025
import pandas as pddf = pd.read_csv("mag_preciosagroindustriacacao_2025junio.csv", sep=";")print(df.head())print(df.info())
PACC_ANIO PACC_MES DPA_PROVINCIA DPA_CANTON PACC_PRODUCTO \
0 2012 Enero El Oro Arenillas Cacao seco mezclado
1 2012 Enero El Oro Arenillas Cacao seco mezclado
2 2012 Enero El Oro El Guabo Cacao seco mezclado
3 2012 Enero El Oro El Guabo Cacao seco mezclado
4 2012 Enero El Oro Machala Cacao seco mezclado
PACC_PRESENTACION PACC_TIPO PACC_PRECIO_USD PACC_USD_KG
0 Quintal de 100,00 libras Compra 71.41 1.57
1 Quintal de 100,00 libras Venta 74.06 1.63
2 Quintal de 100,00 libras Compra 73.75 1.63
3 Quintal de 100,00 libras Venta 84.00 1.85
4 Quintal de 100,00 libras Compra 75.00 1.65
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 26246 entries, 0 to 26245
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PACC_ANIO 26246 non-null int64
1 PACC_MES 26246 non-null object
2 DPA_PROVINCIA 26246 non-null object
3 DPA_CANTON 26246 non-null object
4 PACC_PRODUCTO 26246 non-null object
5 PACC_PRESENTACION 26246 non-null object
6 PACC_TIPO 26246 non-null object
7 PACC_PRECIO_USD 26246 non-null float64
8 PACC_USD_KG 26246 non-null float64
dtypes: float64(2), int64(1), object(6)
memory usage: 1.8+ MB
None
# Agrupar por provincia y cantón y calcular promediodf_group = ( df.groupby(["DPA_PROVINCIA", "DPA_CANTON"], as_index=False)["PACC_PRECIO_USD"] .mean() .round(2))# Renombrar columnas a formato source, target, weightdf_group.columns = ["source", "target", "weight"]# Agrupar por provincia y calcular promediodf_group_prov = ( df.groupby(["DPA_PROVINCIA"], as_index=False)["PACC_PRECIO_USD"] .mean() .round(2))# Agregar columna fija con el país como nodo raízdf_group_prov["Pais"] ="Ecuador"# Reordenar columnas para mantener jerarquíadf_group_prov = df_group_prov[["Pais","DPA_PROVINCIA","PACC_PRECIO_USD"]]# Renombrar columnas a formato source, target, weightdf_group_prov.columns = ["source", "target", "weight"]# Concatenar niveles País-Provincias y Provincias-Cantonesdf_res = pd.concat([df_group_prov, df_group])# Eliminar relaciones redundantes (self-links)df_res = df_res[df_res["source"] != df_res["target"]]
from d3blocks import D3Blocksd3 = D3Blocks()import plotly.io as piopio.renderers.default ="notebook"
---------------------------------------------------------------------------ModuleNotFoundError Traceback (most recent call last)
Cell In[3], line 1----> 1fromd3blocksimport D3Blocks
2 d3 = D3Blocks()
3importplotly.ioaspioModuleNotFoundError: No module named 'd3blocks'
from d3blocks import D3Blocks## Initialized3 = D3Blocks()d3.circlepacking(df_res , filepath="circular.html", #hTML SALIDA overwrite=True,#notebook=True, border = {"color": "#000000", # Color del borde (negro en este caso)"width": 1.5, # Grosor del borde"fill": "#DDFF00C2", # Relleno r"padding": 2# Tamaño/separación},font={"size": 12, "type":"sans-serif"},title="Cacao en el Ecuador",save_button=False)
[d3blocks] >INFO> Cleaning edge_properties and config parameters..
[d3blocks] >INFO> Cleaning edge_properties and config parameters..
[d3blocks] >INFO> Initializing [Circlepacking]
[d3blocks] >INFO> filepath is set to [C:\Users\meagu\AppData\Local\Temp\d3blocks\circular.html]
[d3blocks] >INFO> Convert to DataFrame.
[d3blocks] >INFO> Node properties are set.
[d3blocks] >INFO> Edge properties are set.
[d3blocks] >INFO> File already exists and will be overwritten: [C:\Users\meagu\AppData\Local\Temp\d3blocks\circular.html]
[d3blocks] >INFO> Open browser: C:\Users\meagu\AppData\Local\Temp\d3blocks\circular.html