import pandas as pd
import plotly.express as px
import plotly.io as pio
import numpy as np
pio.renderers.default = "notebook"Un gráfico de densidad es una representación de la distribución de una variable numérica.
Se basa en un estimador de densidad kernel (KDE) para mostrar la función de densidad de probabilidad de la variable.
Es una versión suavizada del histograma y se utiliza en los mismos contextos.
0.1 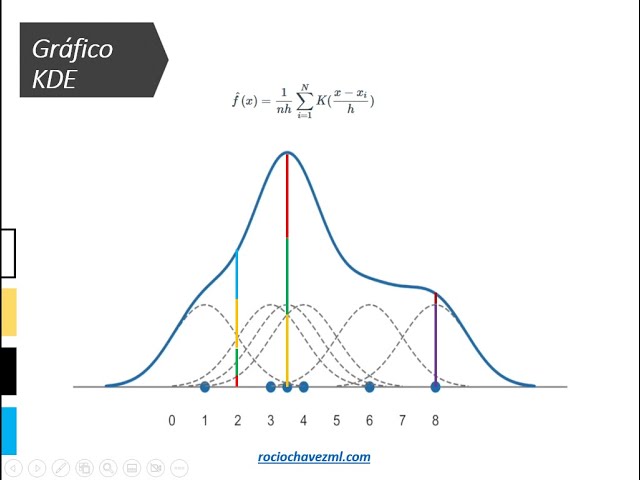
0.2 Características
Los gráficos de densidad se usan para analizar la distribución de una o pocas variables.
Revisar la distribución de tus variables es probablemente la primera tarea exploratoria al trabajar con un nuevo dataset, pues entrega mucha información sobre los datos.
Existen múltiples formas de distribución: simétrica, sesgada a la derecha o izquierda, multimodal, uniforme, etc.
Explorarlas también ayuda a detectar errores en los datos, como distribuciones en “peine” que suelen indicar redondeo o algún procesamiento inadecuado.
Para comparar variables: - 1 a 3 distribuciones se pueden mostrar en el mismo gráfico usando transparencia.
- Con más de 3, el gráfico se vuelve ilegible → en este caso es mejor usar violin plots, boxplots, ridgeline plots o small multiples.
0.3 Errores Comunes
No ajustar el parámetro de ancho de banda (bandwidth):
Dependiendo del valor, la curva puede ocultar detalles (suavizado excesivo) o mostrar demasiado ruido (suavizado insuficiente).Comparar demasiados grupos en un solo gráfico:
Más de 3 o 4 curvas superpuestas generan un gráfico confuso.Uso excesivo de colores:
Paletas muy variadas distraen. Mejor usar colores simples y bien diferenciados.
1 Dataset: Precios Agroindustria de Cacao (2012 - 2025)
Archivo: MAG_PreciosAgroindustriaCacao_2025Junio.csv
Fuente: Ministerio de Agricultura y Ganadería (MAG), Ecuador
Última actualización: Junio 2025
import pandas as pd
df = pd.read_csv("mag_preciosagroindustriacacao_2025junio.csv", sep=";")
print(df.head())
print(df.info()) PACC_ANIO PACC_MES DPA_PROVINCIA DPA_CANTON PACC_PRODUCTO \
0 2012 Enero El Oro Arenillas Cacao seco mezclado
1 2012 Enero El Oro Arenillas Cacao seco mezclado
2 2012 Enero El Oro El Guabo Cacao seco mezclado
3 2012 Enero El Oro El Guabo Cacao seco mezclado
4 2012 Enero El Oro Machala Cacao seco mezclado
PACC_PRESENTACION PACC_TIPO PACC_PRECIO_USD PACC_USD_KG
0 Quintal de 100,00 libras Compra 71.41 1.57
1 Quintal de 100,00 libras Venta 74.06 1.63
2 Quintal de 100,00 libras Compra 73.75 1.63
3 Quintal de 100,00 libras Venta 84.00 1.85
4 Quintal de 100,00 libras Compra 75.00 1.65
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 26246 entries, 0 to 26245
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PACC_ANIO 26246 non-null int64
1 PACC_MES 26246 non-null object
2 DPA_PROVINCIA 26246 non-null object
3 DPA_CANTON 26246 non-null object
4 PACC_PRODUCTO 26246 non-null object
5 PACC_PRESENTACION 26246 non-null object
6 PACC_TIPO 26246 non-null object
7 PACC_PRECIO_USD 26246 non-null float64
8 PACC_USD_KG 26246 non-null float64
dtypes: float64(2), int64(1), object(6)
memory usage: 1.8+ MB
None2 Iteración 1
import plotly.figure_factory as ff
# Extraer los datos en una lista
data = [df["PACC_PRECIO_USD"].dropna()]
# Nombres de la serie
labels = ["Precio USD Cacao"]
# Crear gráfico de densidad
fig = ff.create_distplot(
data,
labels,
bin_size=30, # tamaño de bin para histograma
show_hist=False, # desactiva histograma
show_rug=False # desactiva rug plot
)
# Título y ejes
fig.update_layout(
title="Gráfico de Densidad (KDE) de Precio USD Cacao",
xaxis_title="Precio en USD Cacao",
yaxis_title="Densidad",
plot_bgcolor="white",
paper_bgcolor="white"
)
fig.show()
3 Iteración 2
import plotly.figure_factory as ff
# Extraer la columna de precios, eliminando nulos
x = df["PACC_PRECIO_USD"].dropna()
# Formato para ff.create_distplot (necesita lista de listas)
hist_data = [x]
group_labels = ['Precio USD Cacao']
# Crear distplot SOLO con curva de densidad (KDE)
fig = ff.create_distplot(
hist_data,
group_labels,
show_hist=True, # histograma pon True
show_rug=True # rug plot
)
fig.update_layout(
title="Gráfico de Densidad (KDE) de Precio USD Cacao",
xaxis_title="Precio en USD Cacao",
yaxis_title="Densidad",
)
fig.show()4 Iteracion 3
5 Agrege al grafico una linea que represente la media y otra la mediana.
import plotly.figure_factory as ff
import plotly.graph_objects as go
import numpy as np
# Extraer la columna de precios, eliminando nulos
x = df["PACC_PRECIO_USD"].dropna()
# Número de bins con la regla de la raíz cuadrada
n = len(x)
nbins = int(np.sqrt(n))
# Calcular media y mediana
mean_val = x.mean()
median_val = x.median()
# Formato para ff.create_distplot
hist_data = [x]
group_labels = ['Precio USD Cacao']
# Crear distplot con histograma + KDE
fig = ff.create_distplot(
hist_data,
group_labels,
bin_size=(x.max() - x.min()) / nbins, # bins por raíz de n
show_hist=True,
show_rug=False
)
# Añadir línea de la media
fig.add_vline(
x=mean_val,
line=dict(color="blue", width=2, dash="dash"),
annotation_text="Media",
annotation_position="top left"
)
# Añadir línea de la mediana
fig.add_vline(
x=median_val,
line=dict(color="red", width=2, dash="dot"),
annotation_text="Mediana",
annotation_position="top right"
)
# Títulos y estilo
fig.update_layout(
title="Histograma + Curva de Densidad (KDE) de Precio USD Cacao",
xaxis_title="Precio en USD Cacao",
yaxis_title="Densidad",
plot_bgcolor="white",
paper_bgcolor="white"
)
fig.show()import plotly.figure_factory as ff
import numpy as np
# Extraer la columna de precios, eliminando nulos
x = df["PACC_PRECIO_USD"].dropna()
# Número de bins con la regla de la raíz cuadrada
n = len(x)
nbins = int(np.sqrt(n))
# Calcular media y mediana
mean_val = x.mean()
median_val = x.median()
# Formato para ff.create_distplot
hist_data = [x]
group_labels = ['Precio USD Cacao']
# Crear distplot con histograma + KDE en color café
fig = ff.create_distplot(
hist_data,
group_labels,
bin_size=(x.max() - x.min()) / nbins, # bins ≈ √n
show_hist=True,
show_rug=False,
colors=["saddlebrown"] # color café
)
# Línea para la media (anotación abajo izquierda)
fig.add_vline(
x=mean_val,
line=dict(color="blue", width=2, dash="dash"),
annotation_text="Media",
annotation_position="bottom left",
annotation_font=dict(color="blue", size=14),
)
# Línea para la mediana (anotación arriba derecha)
fig.add_vline(
x=median_val,
line=dict(color="red", width=2, dash="dot"),
annotation_text="Mediana",
annotation_position="top right",
annotation_font=dict(color="red", size=14),
annotation_bgcolor="white"
)
# Títulos y estilo
fig.update_layout(
title="Histograma + Curva de Densidad (KDE) de Precio USD Cacao",
xaxis_title="Precio en USD Cacao",
yaxis_title="Densidad",
plot_bgcolor="white",
paper_bgcolor="white"
)
fig.show()import plotly.figure_factory as ff
import numpy as np
# Extraer la columna de precios, eliminando nulos
x = df["PACC_PRECIO_USD"].dropna()
# Número de bins con la regla de la raíz cuadrada
n = len(x)
nbins = int(np.sqrt(n))
# Calcular media y mediana
mean_val = x.mean()
median_val = x.median()
# Formato para ff.create_distplot
hist_data = [x]
group_labels = ['Precio USD Cacao']
# Crear distplot con histograma + KDE en color café
fig = ff.create_distplot(
hist_data,
group_labels,
bin_size=(x.max() - x.min()) / nbins, # bins ≈ √n
show_hist=True,
show_rug=False,
colors=["saddlebrown"] # color café
)
# Cambiar color del histograma (primer trace)
fig.data[0].marker.color = "gray"
# Cambiar color de la curva KDE (segundo trace)
fig.data[1].line.color = "saddlebrown"
# Línea para la media
fig.add_vline(
x=mean_val,
line=dict(color="blue", width=2, dash="dash")
)
# Línea para la mediana
fig.add_vline(
x=median_val,
line=dict(color="red", width=2, dash="dot")
)
# Anotación para la media (posición y fija en 0.21)
fig.add_annotation(
x=mean_val + 60,
y=0.021,
text=f"Media = {mean_val:.2f}",
showarrow=False,
font=dict(color="blue", size=14),
bgcolor="white"
)
# Anotación para la mediana (posición y fija en 0.21 pero desplazada un poco)
fig.add_annotation(
x=median_val-60,
y=0.021,
text=f"Mediana = {median_val:.2f}",
showarrow=False,
font=dict(color="red", size=14),
bgcolor="white"
)
# Títulos y estilo
fig.update_layout(
title="Histograma + Curva de Densidad (KDE) de Precio USD Cacao",
xaxis_title="Precio en USD Cacao",
yaxis_title="Densidad",
plot_bgcolor="white",
paper_bgcolor="white"
)
fig.show()